Turner Luke

University of Texas at Austin, MS: Data Science
University of Wisconsin - Madison, BS: Chemical Engineering, BS: Chemistry
Portfolio
End-to-End Data Engineering Pipeline

An end-to-end data engineering project that transforms messy, unstructured data into a robust, structured data warehouse using modern tools such as dbt, Polars, duckdb, pydantic, and evidence.dev. The project encompasses data ingestion, cleaning, transformation, and analysis—culminating in interactive dashboards that deliver actionable insights to business stakeholders. Demonstrates an ability to build scalable, reproducible data pipelines and optimize data assets for performance and clarity.
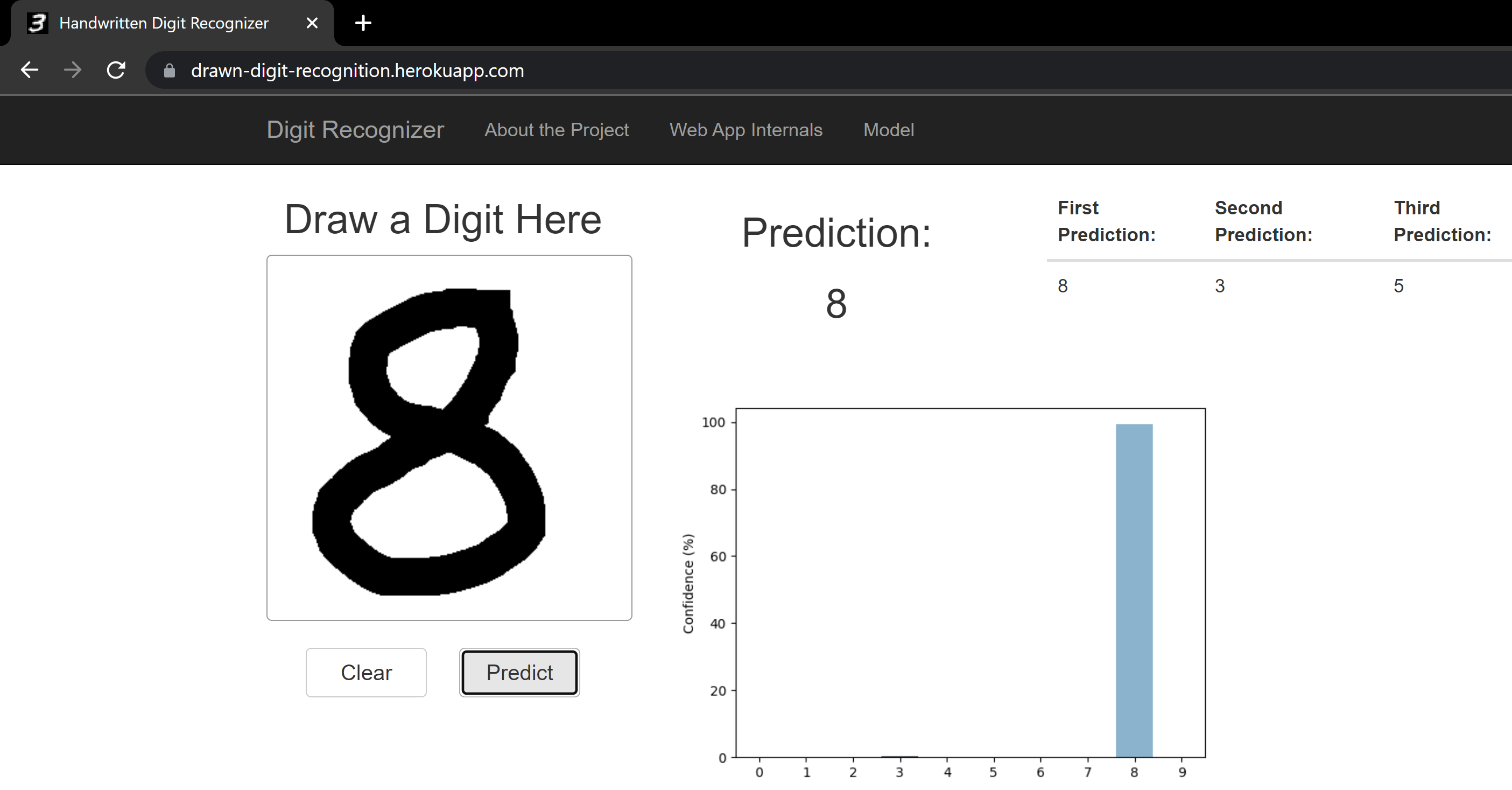
Digit Recognition Web App


A web app, deployed on streamlit, takes the users input as a digit drawing on a canvas and outputs a prediction. This app is my over-engineered take on the “Hello World” of neural networks, digit prediciton from the MNIST dataset, which takes the project all the way to a deployed model on a polished website. This web app went through many iterations, starting as a Flask app on Heroku, to the same app on Render, landing now on a streamlit app. The previous implementation in Flask can be found in the GitHub repo.
Data Structures and Algorithms Projects
A collection of projects created during coursework for a graduate-level data structures and algorithms course.
ML Algorithms

A collection of self-made machine learning algorithmns. Algorithms are created with the intent of better understanding the processes behind each machine learning algorithm, as well as to communicate technical data science information.
Currently the following algorithms have constructed:
- K-Nearest Neighbors Classification
- K-Nearest Neighbors Regression
- K-Means Clustering
- Multi-Layer Perceptron Classifier Neural Network
- Multi-Layer Perceptron Regressor Neural Network
- Gradient Descent Least-Squares Optimization with Regularization
I got my start in Data Science blogging by writing about these algorithms on Towards Data Science, see my Medium posts here.
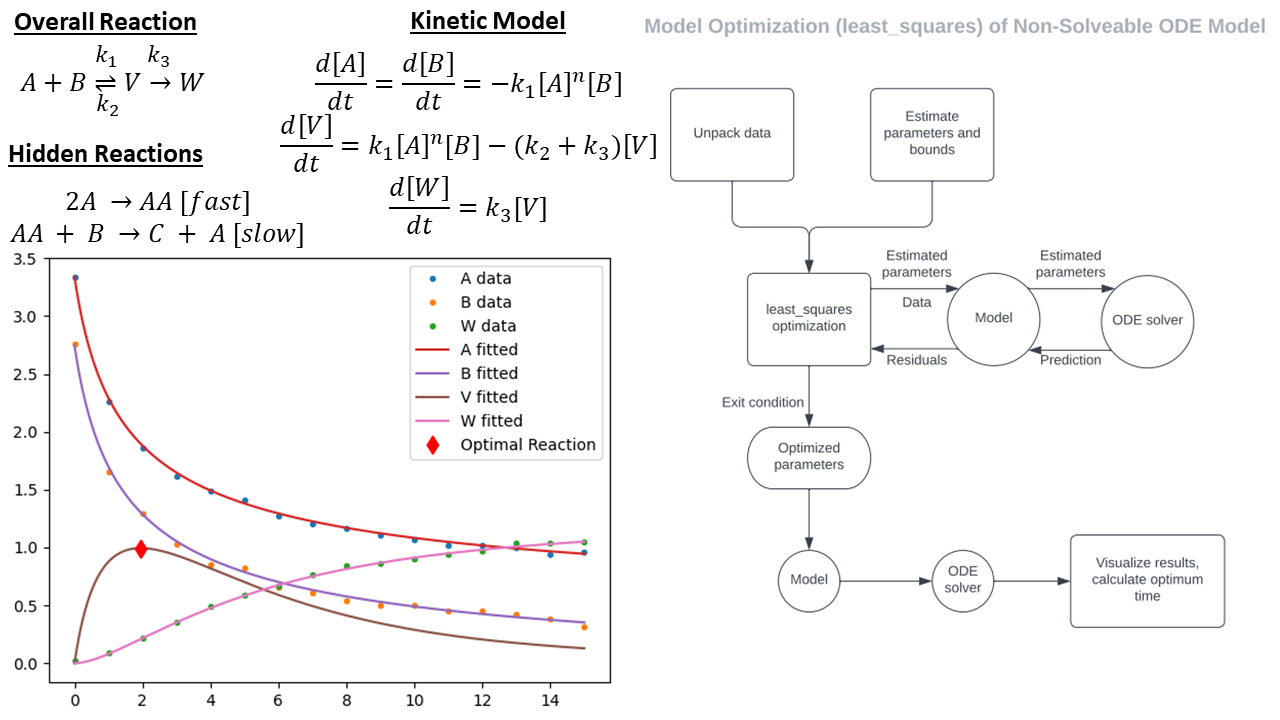
Computational Presentations
A repository of my presentations from spring 2021 teaching computational coursework to chemical engineering undergraduate students. The course topics were set by the university, however these presentations and the examples with their code were made entirely from scratch.
Coursework coved a variety of numerical methods and data operations, including but not limited to:
- Coding fundamentals
- Data visualizations
- Data operations
- Interpolation
- Solving nonlinear systems of equations
- Numerical integration
- Nonlinear parameter estimation (least squares optimization)
- Numerical solutions to differential equations
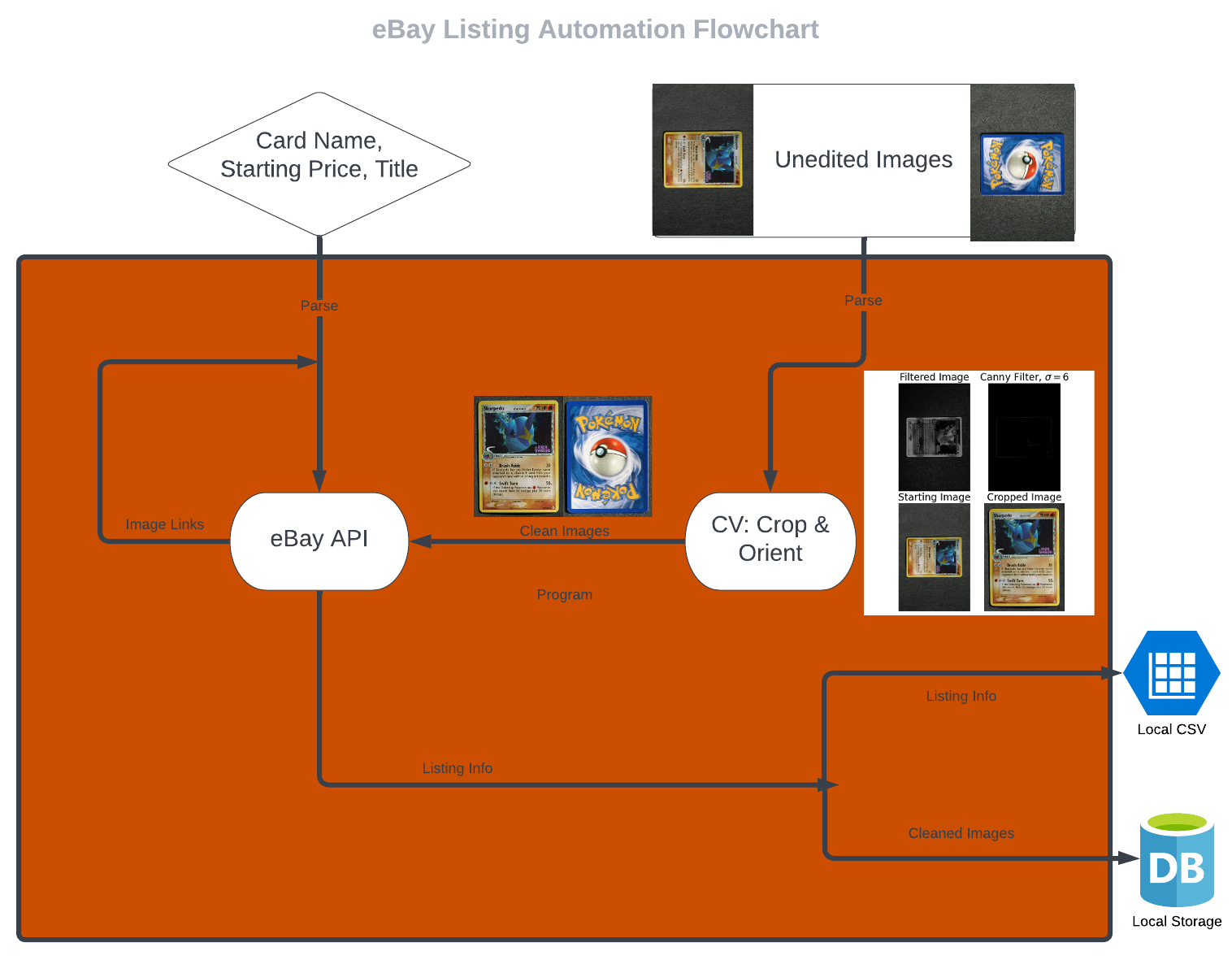
Pokemon Card eBay Listing Automation
A use-specific automation of a repetitive e-commerce task utilizing an open-source API and computer vision. Use has saved approximately 50 hours of work thusfar, and counting.
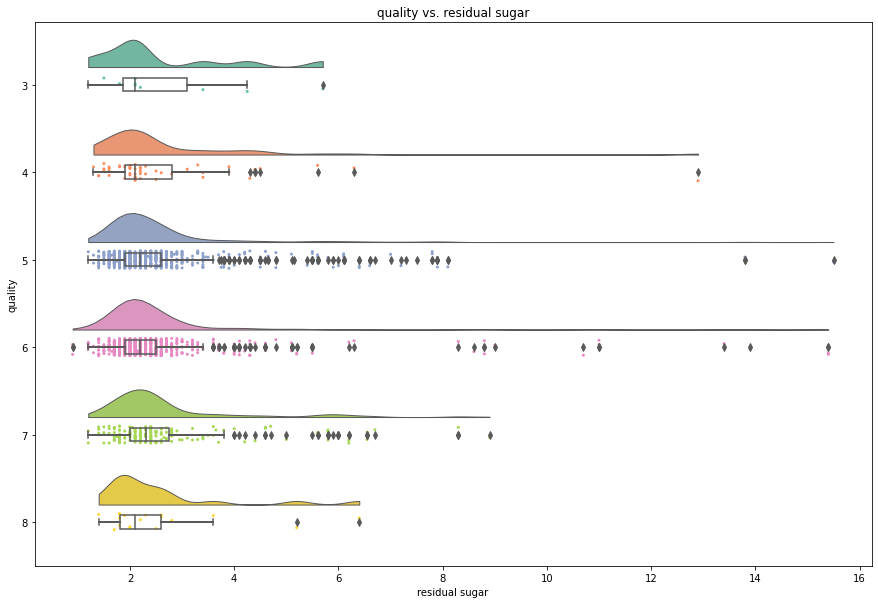
Red Wine Quality Classification
An analysis of the UCI machine learning repository’s red wine quality dataset, to classify wine qualities from their characteristics.
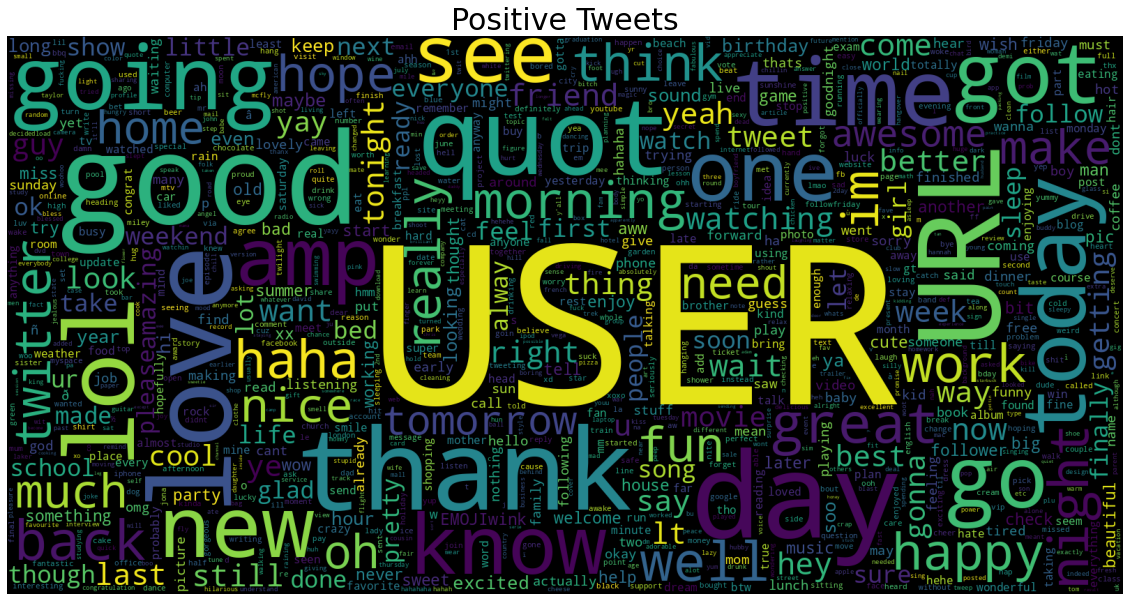
Twitter Sentiment Analysis
An NLP machine learning pipeline for the Sentiment140 dataset.
SpaceX Landing Analysis
An analysis of datasets on SpaceX launches and landings. Utilizes a wide array of data science concepts, including: Jupyter notebooks, webscraping, APIs, data cleaning, interactive visualizations, dashboard creation, SQL database operation, and ML predictions.